

Posted on 23 June 2021, updated on 20 September 2023.
The controller pattern
I won't write too much about the concept, coined by WeaveWork, but just remind us of a few key ideas. It mostly works in the same way as Kubernetes :
- Declarative: instead of relying on cook recipes (looking at you Ansible), you should just declare what you want. In that case, it might be Kubernetes objects, Terraform layers or Aws CloudFormation stacks...
- Versioned: since git is the main source of truth for software development, why not apply this good practice for infrastructure ? Therefore, you'll store these definitions in a repository, on which you can use classic access control, pull request, etc... Moreover, you can rollback a change on your infrastructure with a simple git revert.
- Control loop: once declared, something needs to assure that your current infrastructure matches the new desired state, it is the concept of a Controller! The GitOps tool will periodically check both the current and desired state of your infra, compute the difference and act accordingly to reduce the gap. Therefore, it can both deploy a new reviewed change, but also protect you against unwanted manual change on your infrastructure, reverting it eventually. For Kubernetes, it is as simple as applying the desired manifests if they don't match.
Pull VS Push pipelines
An important consideration if you want to implement a GitOps pattern in your delivery process is the pull vs push. For a classic CI/CD pipeline, you're mostly pushing the modification from upstream git repository to downstream. Here is an example if you need to update a library used in your applications:
- A library publishes a new version, and might, through a CI job (but often manually), create a Merge Request on the app using it
- Once the MR is merged, it triggers both Continuous Integration and Continuous Delivery jobs, leading to the release of a new deployment artifact, mostly a Docker/OCI image these days.
- The new release triggers a Continuous Deployment job, and your app is online with the updated library
While this approach is straight forward, logical and easy to implement, it has a few drawbacks :
- It is non-scalable for your library to create MR on all the downstream projects.
- If one of you CI/CD jobs fails, the cluster won't use the app shown on your repository but an older version.
- If someone manually changes the app on the cluster (for debugging purposes for example) but forget to revert the changes, you won't be able to catch the mistake.
In the pull approach, reverse the whole process : the downstream project regularly pulls news from upstream and adapts in consequence. If we update our example:
- The library publishes a new version (a new GitHub release for example).
- The app repository has a bot which regularly checks the library repository, and if the app uses the last version. If necessary, it creates a PR, merging it automatically for fixed versions if the CI passes. Once merged, the new code is released into its container form with a classic CI/CD pipeline.
- On the infrastructure, another bot notices the new release and updates the desired version in the cluster.
This approach, core for GitOps, is more robust and secure for your deployments. However, I find it sometimes awkward to use, since you have to design a whole control system for each of your projects, and think backwardstrong> about your delivery workflow.
In practice, I would advise you to use this pattern with caution. It is often way more pragmatic to write a hacky bash script to automate a manual task in your workflow !
Now that you have all the basics that I think are essential to understand and use GitOps, it's time to discover the practical use of one of the tools of the kind, ArgoCD, specialized for Kubernetes.
About ArgoCD
In a nutshell, ArgoCD is a Kubernetes controller, which seeks to synchronize a set of Kubernetes resources in a cluster with the content of a Git repository. It is mostly stateless, since it manages its state through Kubernetes Secrets, ConfigMap and Custom Resources Definitions. I'll cover these in more detail in a few lines.
The main idea is that when you update your Git Repository, ArgoCD will eventually catch the difference and synchronize the current state of the cluster with the target one of the repository. I mentioned eventually because, by default, it only checks the repository every 3 minutes or so, but you can make it more reactive with webhooks.
After noticing the difference, ArgoCD tries to converge to the targeted state, by simply applying the new manifests through the Kubernetes API. That's the whole idea around controllers and CRD in general: your cluster will eventually converge to a stable and wanted state. If set up correctly, ArgoCD will also correct any modification made outside the git repository. Therefore, any manual modification will be erased, you can be assured that your git repository does represent the state of your K8s cluster!
And there is more! What makes ArgoCD a great tool is its web UI. There is also a CLI, but I have to admit that having a simple UI (it's not anything fancy, but it does the job) is quite nice and dev-friendly. You can see how each component of your app is doing, and even follow logs (since the 2.0). It can really help developers to understand why their app doesn't work as expected (failing pod, missing ingress, etc...). That's at least half the value of ArgoCD for me!
It also supports native OAuth authentication, a nice and often underestimated feature !
Installation
The installation is quite straightforward; since it doesn't require any database or external dependencies, apart from the CRD. But the cool part, is that you can bootstrap the installation of ArgoCD with itself 🐣 🐔 🥚 ! ArgoCD will update itself, manage itself and eventually could try to uninstall itself (but would somewhat fail in the middle).
kubectl create namespace argocd
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yamlOr if you prefer Helm for further customization:
helm repo add argo https://argoproj.github.io/argo-helm
helm install --name my-release argo/argo-cdFor a quick test, I would recommend kind for a local Docker based Kubernetes cluster. Or if you have your own cluster you can follow along, with a more complete example on GitHub.
If your Git Repository is private, you’ll need to add some credentials in the ArgoCD configuration, through the ConfigMap. It is also true for private Helm repositories, for example if you use the GitLab Container Registry as an OCI Helm Chart repositories :
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app.kubernetes.io/name: argocd-cm
app.kubernetes.io/part-of: argocd
name: argocd-cm
data:
repositories: |
- type: git
url: https://gitlab.com/padok/config.git
passwordSecret:
key: password
name: repo-3778556307
usernameSecret:
key: username
name: repo-3778556307
- enableOci: true
name: registry.gitlab.com/padok/helm
type: helm
url: registry.gitlab.com/padok/helm
usernameSecret:
key: username
name: repo-2729472638
passwordSecret:
key: password
name: repo-2729472638Useful pattern for managing ArgoCD applications
The main Resources of ArgoCD are Applications, which simply represent a path to a git repository, the cluster on which the app should run, a destination namespace and a few other options. Once the Application Resource is declared in the Kubernetes cluster (through kubectl, argocd CLI or the Web UI), Arg will watch this repository and create resources accordingly.
Here are some classic patterns for your Application :
Manifests
The simplest one: just drop your Kubernetes manifests into a folder, create an application resource, and you're good to go. If your manifests are split into sub-folders, do not worry, there is an optional recursive option. You also select the Argo project (default should be good for now), the targeted cluster (a single ArgoCD instance can manage several clusters) and a namespace.
Upload your code, add the app, and it works. For example, I have in my repositories a few YAML manifests to deploy cert-manager:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: cert-manager
spec:
destination:
namespace: cert-manager
name: in-cluster
project: default
source:
# directory:
# recurse: false
path: cert-manager/cert-manager/
repoURL: 'https://github.com/dixneuf19/brassberry-kubernetes-cluster-state'
targetRevision: HEAD
syncPolicy:
automated:
prune: false
selfHeal: true
syncOptions:
- CreateNamespace=trueAnd my Kubernetes manifests are stored in the specified sub-path:
brassberry-kubernetes-cluster-state.git
.
├── cert-manager
└── cert-manager
├── acme-cluster-issue.yaml
├── cert-manager.yaml
└── staging-acme-cluster-issuer.yaml
This method is straight-forward ! You can already tweak the Sync options:
- automated is a map, which if non-null ({} is enough for example), will tell ArgoCD to automatically update the cluster if the source repository changes for this Application.
- automated.prune allows ArgoCD to delete Kubernetes resources, for example if a commit removes a manifest. Use this option once you're familiar with the tool.
- automated.selfHeal by default, ArgoCD only acts on changes in the git repository. However, with this option, it will revert any manual changes made on the cluster. For debugging purposes, you might want to deactivate it.
Helm charts
Deploying plain YAML manifests is fine, but I tend to prefer the templating features of Helm to generate my Kubernetes resources! Thankfully, ArgoCD supports Helm charts out of the box. In the ArgoCD Application, you specify the Helm repository as the source.
To customize it you have three options :
- Hard coding a few variables specifically
- Writing a YAML values.yaml directly into the Application's manifest (YAML in YAML 😕 )
- Referencing a values.yaml file in the same repository as the chart.
For very simple configuration, the first two solutions are OK, but I prefer using the latter, since I want to be able to run helm commands on my own, with ArgoCD, for debug purposes for example. However, since I don't own most of the charts I install (for example ingress-nginx), I need to use a special pattern : Out Of the Shelf charts, or OTS Helm Charts. They also often called Umbrella Charts, but this last terminology is more accurate when you combine several subcharts, or add some new templates.
The idea is quite simple: create a local chart in your repository, with as a dependency the remote chart you want to use ! For this, you only need a Chart.yaml:
# Chart.yaml
apiVersion: v2
name: ingress-nginx
version: 1.0.0 # you may follow the same semantic versionning as the main chart
appVersion: 1.0.0 # same
description: OTS Nginx ingress controller chart
sources:
- https://github.com/kubernetes/ingress-nginx
type: application
dependencies:
- name: ingress-nginx
version: 3.33.0
repository: https://kubernetes.github.io/ingress-nginx
# You can use an "alias" to shorten the name of the subchart
# alias: nginx If you have not much experience with Helm repositories and dependencies management, here a quick usage guide:
- Add the repository if you haven't used it yet:
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx helm repo updateUsually, a repository hosts a few different charts, for example the prometheus-community one.
- In your Chart folder, generate a Chart.lock and download the sub-charts
helm dependency update # if you have already a Chart.lock, and only want to download dependencies # helm dependency buildYou should have a Chart like that:
. ├── Chart.lock ├── charts │ └── ingress-nginx-3.33.0.tgz ├── Chart.yaml └── values.yaml - Now you can write your values.yaml as usual, but prefixing all the config of the subchart by its name (or its alias if used):
# values.yaml ingress-nginx: # if alias is set in Chart.yaml, can be replaced by it controller: # for example nginx:... updateStrategy: rollingUpdate: maxUnavailable: 1 type: RollingUpdate # ...
You can now install your chart from your machine as usual:
helm template my-release . -f values.yaml # to debug
helm upgrade --install my-release . -f values.yamlTo manage this chart with ArgoCD you need to reference your own repository, with the relative path to the values.yaml (you can specify several values files if you want to factorize your code base).
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: ingress-nginx
spec:
project: default
source:
path: nginx/ingress-nginx/
repoURL: 'https://github.com/dixneuf19/brassberry-kubernetes-cluster-state'
targetRevision: HEAD
helm:
valueFiles:
- values.yaml
# you might refer to a ../values.shared.yaml
destination:
namespace: nginx
name: in-cluster
syncPolicy:
automated: {} # same options as before
You also get a service oriented view, useful for beginners !
A few ways to handle Chart dependencies:
While I was writing this article, I found out that ArgoCD handles Helm Charts dependencies differently if you provide a Chart.lock and/or a charts/ folder.
First of all, if you don’t provide any of these, ArgoCD will smartly pull the right chart from the given repository (it looks for the classic index.yaml at the repository url). However, it means that you must omit the Chart.lock, which is similar to a package-lock.json in Node, that helps to achieve reproducible builds.
In most cases, you should be fine without it, but if it is a requirement or a good practice you want to enforce, you will need to commit the Chart.lock in your versioning system.
In that case, you will encounter an error about ArgoCD not finding the Helm repository! In that case, it isn’t smart enough to find the repo by itself… It tries to run the helm repo add .. and lacks some information.
A clean solution is to add permanently the remote chart repositories to ArgoCD. That way, ArgoCD will run a helm repository add && helm repository update before trying to build your chart.
You can do it from the CLI/GUI, but if you manage ArgoCD with itself, you need to modify your manifest or Helm chart of your installation.
# ...
---
apiVersion: v1
kind: ConfigMap
metadata:
name: argocd-cm
data:
application.instanceLabelKey: argocd.argoproj.io/instance
repositories: |
- type: helm
name: argo
url: https://argoproj.github.io/argo-helm
- type: helm
url: https://charts.helm.sh/stable
name: stable
- type: helm
url: https://kubernetes.github.io/ingress-nginx
name: ingress-nginxOnce it's set up, you can forget about it and enjoy automatic updates with your dependency bot which will also update the Chart.lock when new versions are available.
Lastly, if you save the charts/ folder in your git repository, ArgoCD will blindly use the charts in archive format to deploy the workload. I don't recommend this technique since if you forget to add the charts/ folder for each update, your app won't really get upgraded.
For example, bots which automate dependency upgrades like Renovate will not run a helm dependency build when opening a PR with the updated Chart.yaml and Chart.lock !
However, I had performance issues with the former technique on ARM, and I ended up using this solution for my personal cluster hosted on a few Raspberry Pi. Hopefully I got a GitHub Action doing the helm dependency build, updating the charts/ folder automatically for me.
I find these behaviors quite strange and confusing, and might take some time to review the code of ArgoCD to eventually open an issue or PR...
A last interesting note about Helm and ArgoCD: it already supports charts in the OCI format (the same format as docker images). It can for example simplify your setup if you need to store an Helm Chart but only have access to an OCI registry such as DockerHub or GitLab Registry.
App of Apps
Now you could add each app individually, but you're missing a part of GitOps. How can we be sure that the app is in the cluster, and not deleted by accident ? It would be great if we add a way to automatically sync my repository of applications with the applications installed in the cluster.
Well, since these Applications are just classic Kubernetes Custom Resources (CRD + Controller), you can manage it with an Application, which will instantiate other Applications : that's an App of Apps ! Moreover, this application can manage itself ! 🤯
Let's say I store all my Applications manifests in a folder :
brassberry-kubernetes-cluster-state.git
.
├── argocd
│ ├── apps
│ │ ├── argocd-server-app.yaml
│ │ ├── cert-manager-app.yaml
├── argocd-apps.yaml
...I just need to declare a new Application resource, synchronizing this folder:
# argocd-apps.yaml
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: argocd-apps
spec:
destination:
namespace: argocd
name: in-cluster
project: default
source:
path: argocd/apps/
repoURL: 'https://github.com/dixneuf19/brassberry-kubernetes-cluster-state'
targetRevision: HEAD
directory:
recurse: true
syncPolicy:
automated:
prune: false
selfHeal: true
syncOptions:
- CreateNamespace=trueIf you save this file into argocd/apps/argocd-apps.yaml it will manage itself! Any new Application manifest in the argocd/apps folder will trigger the deployment of the app and its resources.
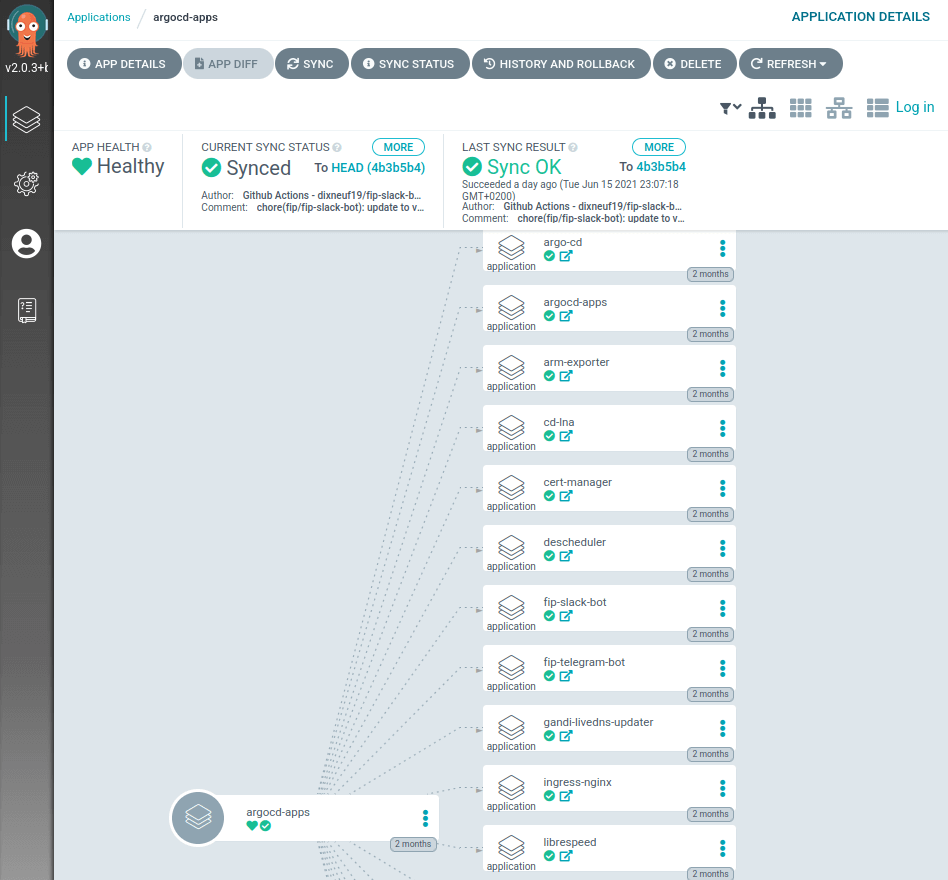
A few other options
Furthermore, ArgoCD also supports other templating solutions such as jsonnet or kustomize, which I won’t cover in detail since I don't have much experience with these technologies. However, the principle remains the same!
ArgoCD in practice
If I took the time to write this article because I found this piece of technology very useful for both my professional and personal project. I'll mostly share my experience with the latter usage. You can find a live example of a Kubernetes cluster managed by ArgoCD on GitHub, running on a RaspberryPi cluster.
First of all, organization is key! I found that having all my manifests and ArgoCD apps organized into specific folders, according to their target namespace is quite clean. However, for bigger projects, you might want to have several repositories. Anyway, I strongly advise separating any code from your cluster declaration: distinguish your Continuous Integration and Continuous Delivery from your Continuous Deployment! In my GitHub project, the repository only stores YAML files.
Since I have a state repository, I needed to update the version of the deployed workload when I released a new version in the upstream application repository. I could have used a Pull pattern, using the newly released Argo CD Image Updater which watches Container registries and updates the downstream repository automatically. However, since the tool is in beta and I don't want to give it write permissions on my repository, I ended up writing a very simple Push workflow, which runs on the upstream repository and commits the updated values.yaml with the released version. Quite hacky and hard to scale, but simpler and faster to implement, that is the compromise I choose.
Moreover, to keep my infrastructure updated, I use the Renovate Bot a lot! In a nutshell, it regularly scans my repositories' dependencies (it supports both Python and Helm, and many more languages) and opens a new PR if there is a new version available. With a good set of tests and GitHub Actions, I can have an infrastructure always in a pristine state!

An issue I ran into was performances on Raspberry Pi. Running on such small (and energy-efficient) machines leads to some new challenges. I obviously needed to find some ARM images for it, but it mostly works fine. However, I had to pay particular attention to the limits/requests of the ArgoCD pods, since they consume quite a lot of resources! Contrary to most simple controllers, ArgoCD can use a lot of RAM and CPU if you manage a lot of applications with it. Nonetheless, its architecture is mostly stateless, so you can scale it quite easily for bigger projects.
Finally, the main drawback of ArgoCD in my opinion is its documentation, which lacks concrete examples and is quite intimidating for newcomers. I hope this article might help some lost souls!
I hope this post helped you understand how GitOps can truly benefit your CI/CD workflow, on the condition that you choose the right place to implement this kind of Pull pattern.
ArgoCD is a great tool for this domain, and can also give a great visualization of the resources running on your cluster. In a read-only mode, I think it's a great tool to help developers understand what happens. You can even read container logs since the last major version!
However, its documentation needs some love, and the GitOps ecosystem still lacks some maturity in terms of practices and tooling to be truly omnipotent in our CI/CD workflows.